Schéma kreslí graphviz sám, z tohoto předpisu.
| 20. 6. - 1. 7. | nedostupný |
| 2. 7. - 9. 7. | v ČR |
| 9. 7. - 20. 8. | mimo ČR, v dosahu Internetu |
| 22. 8. - 25. 8. | spíše nedostupný |
| Datum | Téma | Slidy |
| 2006-02-22 | Úvod, nástroje, metrika kvality překladu | velké k tisku |
| 2006-03-01 | Přehled součástí SMT (statistického strojového překladu) | velké k tisku |
|
Výběr z přednášek Chrise Callison-Burche a Philippa Koehna:
Phrase-based (ngramový, frázový) statistický strojový překlad Extrakce frází Dekódování (hledání optimálního překladu) |
velké
k tisku
velké k tisku velké k tisku |
|
| 2006-03-08 |
Rozdělení témat na zápočtové "projekty".
Do příště: získat (ode mne ap.) literaturu a podrobněji si specifikovat úlohu. |
- |
| 2006-03-15 | První společná debata nad postupem prací ve skupinkách. | - |
| 2006-03-22 |
První společná debata nad podrobnějším zacílením skupinkové práce.
Do příště: základ článku v LaTeXu, zejména titulek, abstrakt, a rozdělení na sekce |
- |
| 2006-03-29 | Druhá debata nad postupem prací. Nutné součásti abstraktu: co řeším za problém, jak ho řeším, jak vyhodnocuji, došlo-li ke zlepšení, a jak to tedy vyšlo. | - |
| 2006-04-05 |
Ukázkové experimenty se strojovým překladem, jako inspirace k vlastním pokusům.
Dohoda o předávání dat. |
velké k tisku |
| 2006-04-12 | Konzultace ve skupinkách. | - |
| 2006-04-19 | Výklad modelu IBM1 pro zarovnání po slovech. | - |
| 2006-04-26 |
Dohoda o plánovaných experimentech.
Do příště: za každou skupinku podrobný seznam experimentů. |
- |
| 2006-05-03 | Konzultace ve skupinkách. | - |
| 2006-05-10 | Konzultace ve skupinkách. | - |
| 2006-05-17 | Hodina odpadá, sportovní den. | - |
| 2006-05-24 |
LaTeX, BibTeX
Shrnutí požadavků na zápočet: viz slidy k první hodině, publikace stačí česky |
- |
\'{a}.Rozdělení a seznam lidí je možné ještě do 22.3. měnit. (Kdo se nezařadí do nějaké skupinky do začátku dubna, nemůže usilovat o zápočet.)
Předběžný přehled o návaznostech mezi skupinkami.
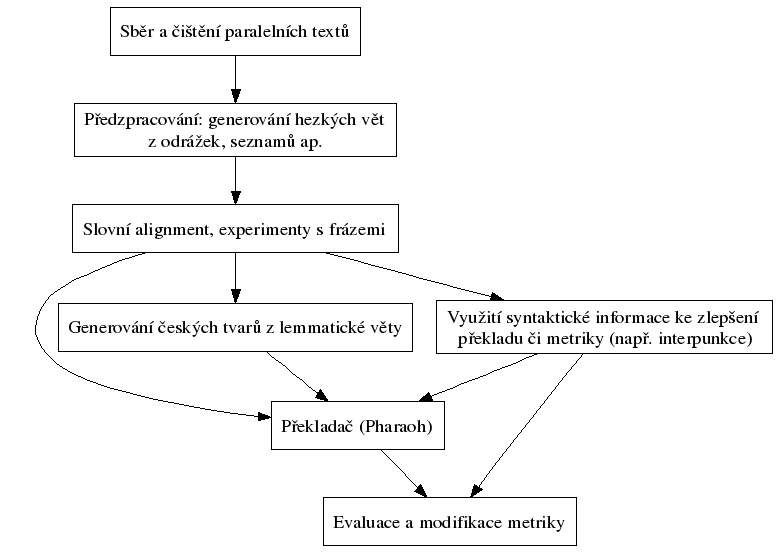
Schéma kreslí graphviz sám, z tohoto předpisu.
Pro zajímavost stav překladů k 1. 3. Jak jsem se díval, nelze číslům úplně věřit. Některé soubory mají matoucí matoucí konce řádků, některé obsahují prázdné řádky a některé obsahují i nepřeložené věty.
| Beneda, Haken | ? + kolegové | Havlíček pre-release | Skokan + kolegové | Kult + Mezsáros + Palyza + Hoblik + Libič | Müller + Koudelka + kolegové | Bojar | |
| 2201 | - | - | - | - | - | 59 | - |
| 2202 | 1 | - | - | 46 | - | - | - |
| 2203 | 18 | - | 18 | 18 | 17 | 18 | - |
| 2211 | 48 | - | - | - | 47 | - | - |
| 2212 | 9 | - | 9 | - | - | - | - |
| 2214 | 13 | - | - | - | - | - | - |
| 2222 | 38 | - | - | - | 37 | - | - |
| 2246 | 10 | - | - | - | 9 | - | - |
| 2248 | 7 | - | - | - | 7 | - | - |
| 2249 | 9 | - | - | - | - | - | - |
| 2303 | 28 | - | - | - | 28 | 29 | 29 |
| 2308 | 24 | - | - | - | - | 44 | 44 |
| 2309 | - | - | - | - | - | 17 | 17 |
| 2313 | - | - | - | - | - | - | 11 |
| 2315 | - | - | - | 12 | - | - | - |
| 2332 | - | - | - | 9 | - | 16 | - |
| 2338 | - | - | - | 28 | 27 | - | - |
| 2393 | - | 11 | - | 10 | - | 27 | - |
| 2399 | - | 27 | - | 28 | - | 29 | - |
| 2406 | - | 50 | - | 22 | 49 | - | - |
| 2435 | - | 10 | - | - | 9 | 12 | - |
| 2436 | - | 11 | - | - | 10 | 11 | - |
| Celkem | 205 | 109 | 27 | 173 | 240 | 262 | 101 |
Základem nám bude Prague Czech-English Dependency Treebank, z něho jsou i ty referenční překlady.
V případě nově dohledávaných textů prosím o konzultaci, řadu elektronických knih už mám zpracovánu, řada však by se ještě najít dala. Nejlepším zdrojem pro anglické knihy je zřejmě Project Gutenberg.
Pro nově získané texty je nutné provést zarovnání po větách (sentence alignment). K dispozici je více nástrojů (viz google), zatím si myslím, že by nám mohla vyhovovat implementace algoritmu Churche a Galea, která je k dispozici v balíku UPLUG. Ještě lepší implementaci jsem ale našel pod názvem hunalign. Umí dokonce cyklicky vylepšovat alignment pomocí slovníku, který se sama naučí.
Základem bude GIZA++.
Pro dekodér Pharaoh jeho autor Philipp Koehn na své domovské stránce poskytuje balíček nástrojů (Pharaoh Training).
Použijeme Pharaoh. Pro stažení je nutné se zaregistrovat, je však volně k dispozici.
Jinou možností by byl ISI ReWrite Decoder, který dělá pouze slovní, nikoli frázový překlad.
Existuje více možností, nevhodnější je asi SRI Language Modelling Toolkit. Opět volně k dispozici po zaregistrování se.
Použijeme Czech Free Morphology.
Použijeme oficiální skript pro NIST evaluaci.